I. Exploring Data
When you analyze one-variable data, always discuss shape, center, and spread. Remember your SOCS!
Look for patterns in the data first, and then look for deviations from those patterns.
When commenting on shape:
* Symmetric is not the same as "equally" or "uniformly" distributed.
* Do not say that a distribution "is normal" just because it looks symmetric and unimodal.
Don't confuse median and mean. They are both measures of center, but for a given data set, they may differ by a considerable amount.
(a) If distribution is skewed right, then mean is greater than median.
(b) If distribution is skewed left, then mean is less than median.
Mean > median is not sufficient to show that a distribution is skewed right.
Mean < median is not sufficient to show that a distribution is skewed left.
Don't confuse standard deviation and variance. Remember that standard deviation units are the same as the data units, while variance is measured in square units.
Know how transformations of a data set affect summary statistics.
(a) Adding (or subtracting) the same positive number k, to (from) each element in a data set increases (decreases) the mean and median by k. The standard deviation and IQR do not change.
(b) Multiplying all numbers in a data set by a constant k multiplies the mean, median, IQR, and standard deviation by k. For instance, if you multiply all members of a data set by four, then the new set has a standard deviation that is four times larger than that of the original data set, but a variance that is 16 times the original variance.
When commenting on shape:
* Symmetric is not the same as "equally" or "uniformly" distributed.
* Do not say that a distribution "is normal" just because it looks symmetric and unimodal.
Treat the word "normal" as a "four-letter word." You should only use it if you are really sure that it's appropriate in the given situation.
When describing a scatterplot:
* Comment on the direction, shape, and strength of the relationship.
* Look for patterns in the data, and then for deviations from those patterns.
A correlation coefficient near 0 doesn't necessarily mean there are no meaningful relationships between the two variables.
Don't confuse correlation coefficient and slope of least-squares regression line.
* A slope close to 1 or -1 doesn't mean strong correlation.
* An r value close to 1 or -1 doesn't mean the slope of the linear regression line is close to 1 or -1.
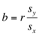
This is on the formula sheet provided with the exam.
* Remember that r2 > 0 doesn't mean r > 0. For instance, if r2 = 0.81, then r = 0.9 or r = -0.9.
You should know difference between a scatter plot and a residual plot.
For a residual plot, be sure to comment on:
* The balance of positive and negative residuals
* The size of the residuals relative to the corresponding y-values
* Whether the residuals appear to be randomly distributed
Given a least squares regression line, you should be able to correctly interpret the slope and y-intercept in the context of the problem.
Remember properties of the least-squares regression line:
* Contains the point , where is the mean of the x-values and is the mean of the y-values.
* Minimizes the sum of the squared residuals (vertical deviations from the LSRL)
Residual = (actual y-value of data point) - (predicted y-value for that point from the LSRL)
Realize that logarithmic transformations can be practical and useful. Taking logs cuts down the magnitude of numbers. Also, if there is an exponential relationship between x and y (y=abx), then a scatterplot of the points {(x,log y)} has a linear pattern.
If the relationship between x and y is described by a power function (y=axb), then a scatterplot of (log x, log y) will have a linear pattern.